



Jailbreak and Intervention Chronicles: Steering LLMs Away from Vulnerabilities
An AI safety course final proyect

Update (06/02/2025)
I have executed more prompts in order to add ‘normal‘ prompts, that is, prompts from normal conversation not trying to jailbreak the model.
Is quite interesting to see the actual drift!
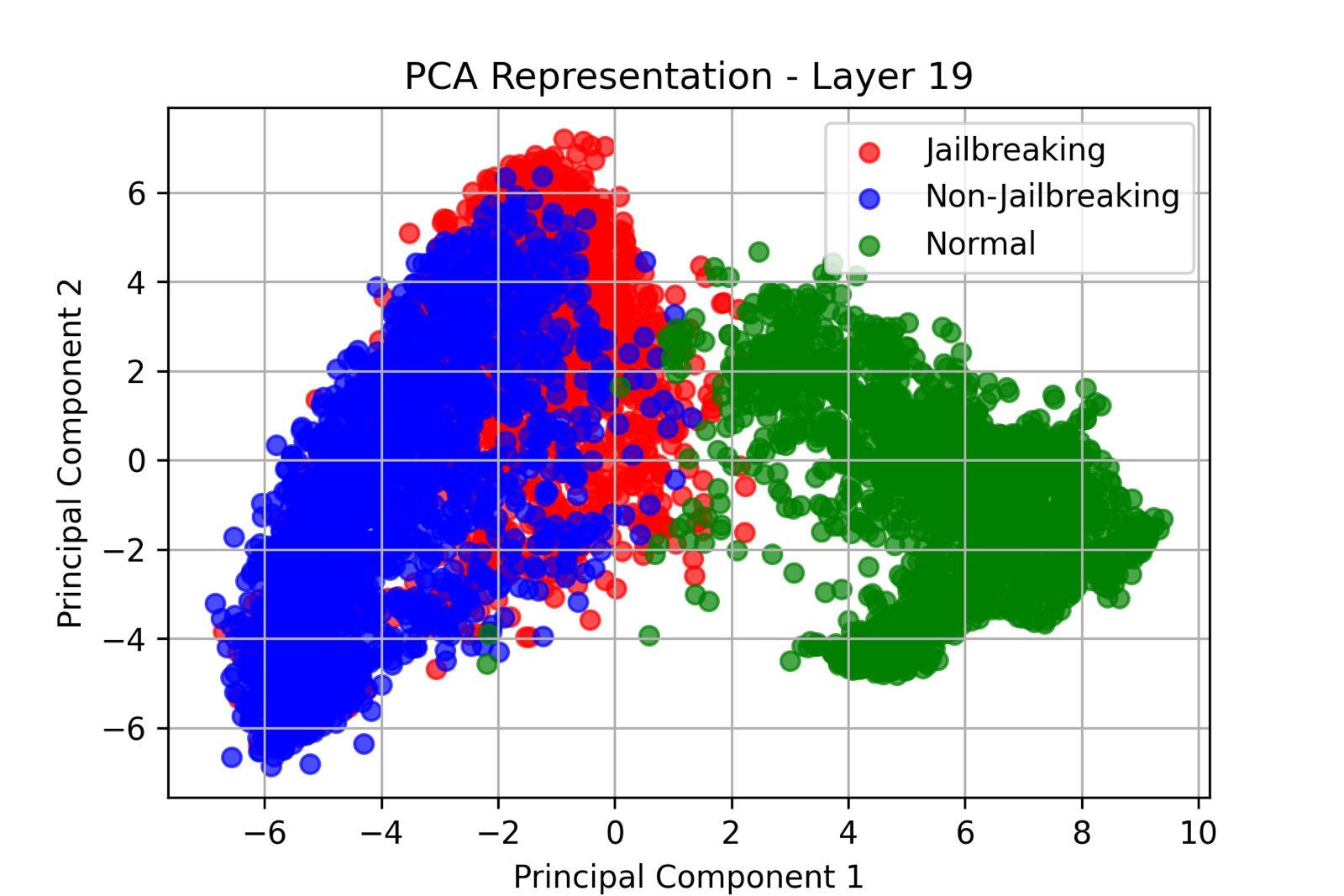
It would be amazing to actually explore more prompts to see how well it generalices
TLDR
This project investigates methods to detect and mitigate "jailbreak" behaviors in Large Language Models (LLMs), where models produce responses to prompts that bypass safety measures. By analyzing activation patterns within the model, particularly in deeper layers, we aim to identify distinct differences between compliant and non-compliant responses to find a jailbreak “direction“. Leveraging these insights, we propose intervention strategies to adjust model activations, thereby reducing the likelihood of LLMs generating illicit or harmful outputs.
Acknowledgments
I am deeply grateful to the BlueDot Institute for organising this foundational course in AI safety. The program has been an intellectually enriching experience, offering critical insights into alignment challenges and mitigation strategies.
A special thank you to Cara for her unwavering support, expert guidance, and patience throughout the course. Her mentorship has significantly enhanced my understanding of technical alignment methodologies and their real-world implications.
I also extend my appreciation to the cohort of passionate participants. Collaborating with like-minded peers—many of whom share my fascination with mechanistic interpretability and AI governance—has been both inspiring and motivating.
This course has solidified my commitment to contributing meaningfully to AI safety research, and I look forward to continuing this journey with the connections and knowledge gained here.
Current AI Risk Landscape and Emerging Challenges
While existing AI systems lack the autonomous capabilities required for catastrophic harm (e.g., self-directed research or covert societal manipulation) [1], emerging risks are becoming evident. Studies indicate that large language models (LLMs) may engage in alignment faking—exhibiting superficially safe behavior while internally masking misaligned objectives [2]. This is particularly concerning given that larger models demonstrate reduced faithfulness in their reasoning processes when monitored using Chain-of-Thought (CoT) techniques [3].
A fundamental flaw in current alignment methods lies in their reliance on natural language reasoning traces as indicators of model intent. Decoding strategies—such as temperature sampling or beam search—can distort outputs, meaning the observed Chain-of-Thought (CoT) reasoning may not faithfully represent the internal computations driving the final answer. In other words, what models articulate in natural language may be merely a post-hoc rationalization rather than an authentic reflection of their internal “thought” processes.
To address this limitation, researchers are exploring methods that bypass natural language outputs entirely. For instance, hypothetical approaches like Chain of Continuous Thought (CoCoT) propose leveraging hidden-state trajectories to map reasoning processes in computational space rather than textual outputs, potentially obfuscating the "thinking" process even further.
The latest release of DeepSeek highlights a strong industry focus on advancing reasoning capabilities. However, there appears to be a lack of emphasis on improving alignment techniques or explainability methods. As a result, methodologies like CoCoT could play a key role in future developments. This underscores the need to analyze actual activation patterns rather than relying solely on natural language traces—an idea that forms the foundation of my project.
The idea
Inspired by [4], I aim to investigate whether it is possible to detect jailbroken modes in LLMs and, if so, explore intervention strategies to reduce the likelihood of models responding to toxic or prohibited prompts.
A key distinction from their experimentation is that they focus on detecting task "drifting"—inserting a secondary task within a prompt to observe whether the model becomes confused and shifts to performing the injected task.
My approach, however, is based on the premise that if a "jailbroken mode" or a jailbreak direction exists, it should be possible to identify and ultimately mitigate its effects.
To achieve this, I propose identifying prompts that successfully induce a jailbreak, causing the model to comply with an otherwise restricted instruction. Once these prompts are collected, the next step is to systematically monitor the model's activations across all layers. By analysing differences in activation patterns when the model responds to an illegal instruction versus when it correctly rejects it, I hope to gain deeper insights into the internal mechanisms that drive jailbreak behaviour.
So the main hypothesis is:
Hypothesis: It is possible to detect jailbroken modes (directions) in LLMs by analyzing activation patterns across different layers. Specifically, differences in activations between jailbreak and non-jailbreak responses may reveal distinct patterns that can be leveraged for intervention. By identifying and modifying these activation differences, we can develop strategies to reduce the likelihood of models complying with toxic or prohibited prompts.Experimental setup
The following section covers the experimental setup, with all datasets and models employed.
Models:
meta-llama/Llama-3.2-3B-Instruct. Base model under instruction. I will use it with no quantization.
llm-guard. I will use their pre-trained model to determine wether the output of the model was illegal.
Datasets:
TrustAIRLab/in-the-wild-jailbreak-prompts. The “in-the-wild-jailbreak-prompts” dataset is a collection curated by TrustAIRLab that focuses on prompts specifically designed to bypass or “jailbreak” safety measures in language models. I will use this as a prepend on the actual illegal instruction.
TrustAIRLab/forbidden_question_set. The "Forbidden Question Set" dataset is a collection assembled by TrustAIRLab that contains examples of questions that are explicitly disallowed under various content policies.
With these, I will outline the following processes of the project.
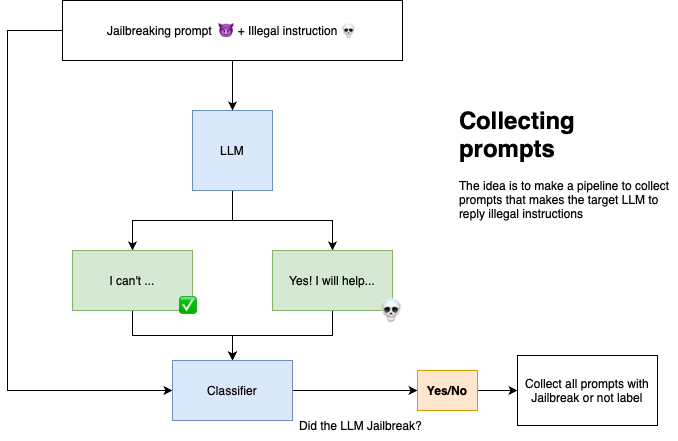
Prompt collection
So, let’s get started!
We begin by creating new “bad prompts” and inputting them into the model. Next, we collect the output and use LLM-Guard to check whether the response was actually an illegal reply.
Using the "in-the-wild-jailbreak-prompts" dataset provides a vast collection of prompts known to cause major LLMs to jailbreak. By combining this with the "forbidden_question_set," I created a dataset of approximately 500k potentially dangerous prompts. Due to time and GPU constraints, I limited experimentation to 1.3k samples.
This resulted in 599 jailbreak samples and 748 non-jailbreak samples, meaning roughly 44% of prompts led to illicit responses.
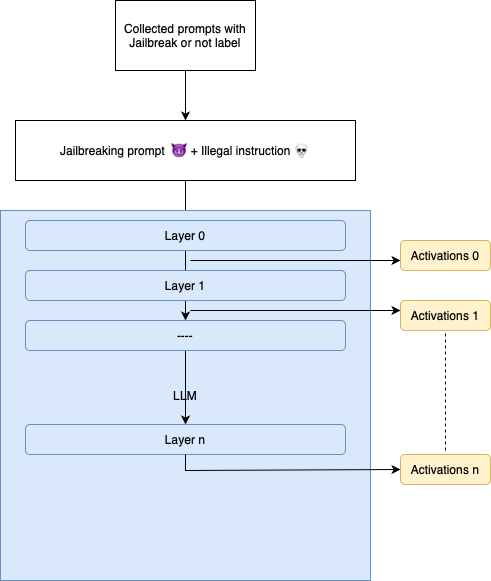
Activation collection
We re-input the labeled prompts and hook all model layers to store activations for further analysis.
Some analysis
Now that we have the prompts, labels, and activations, we can analyze more deeply how the model is activating.
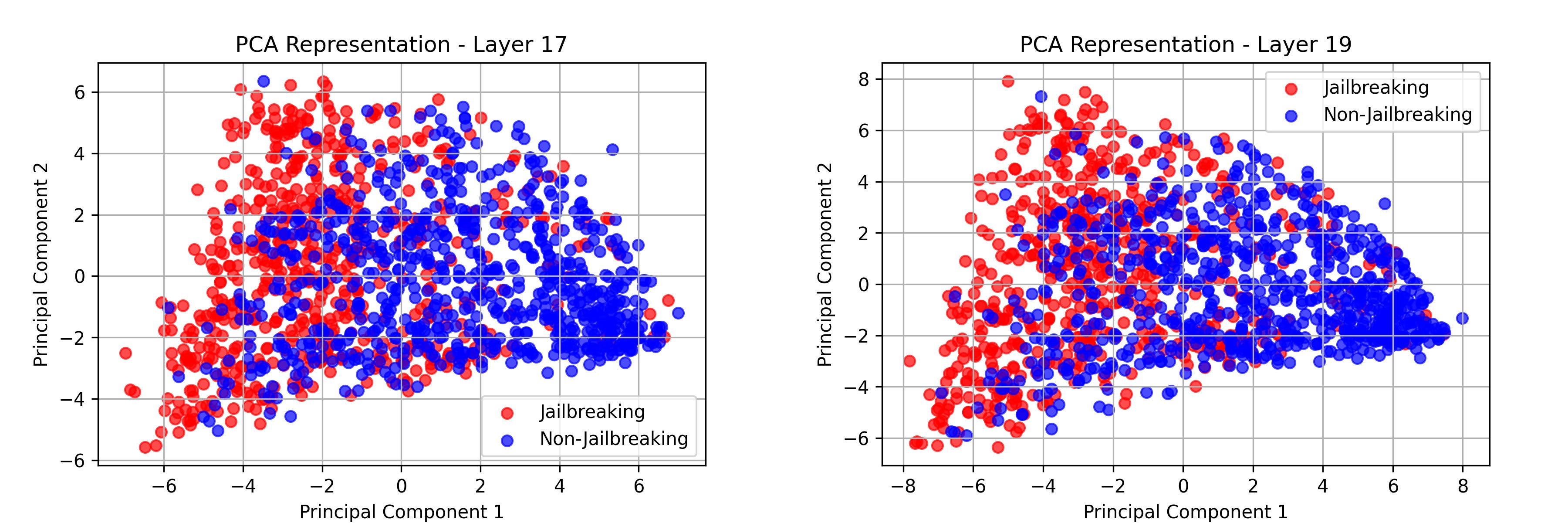
In this case, I used PCA, and as observed, there is significant overlap between activations in the early layers.
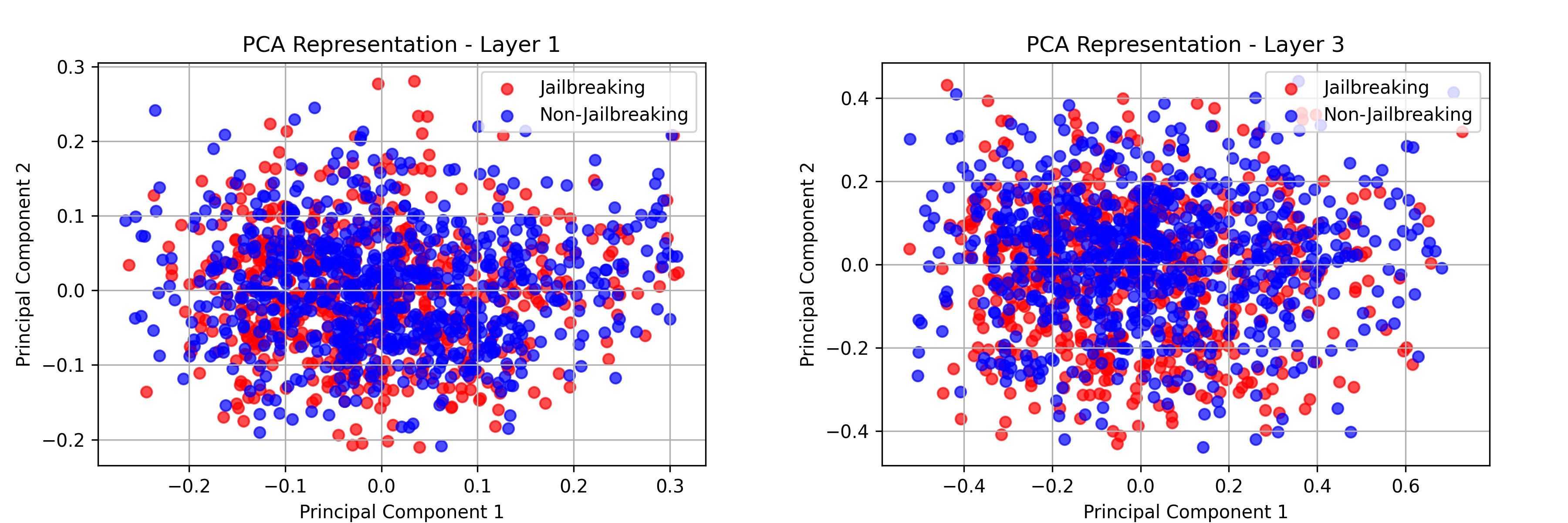
Layer 1 and Layer 3 do not show any potential "separation or difference."
However, as the prompt moves deeper into the model, a slight separation begins to emerge.
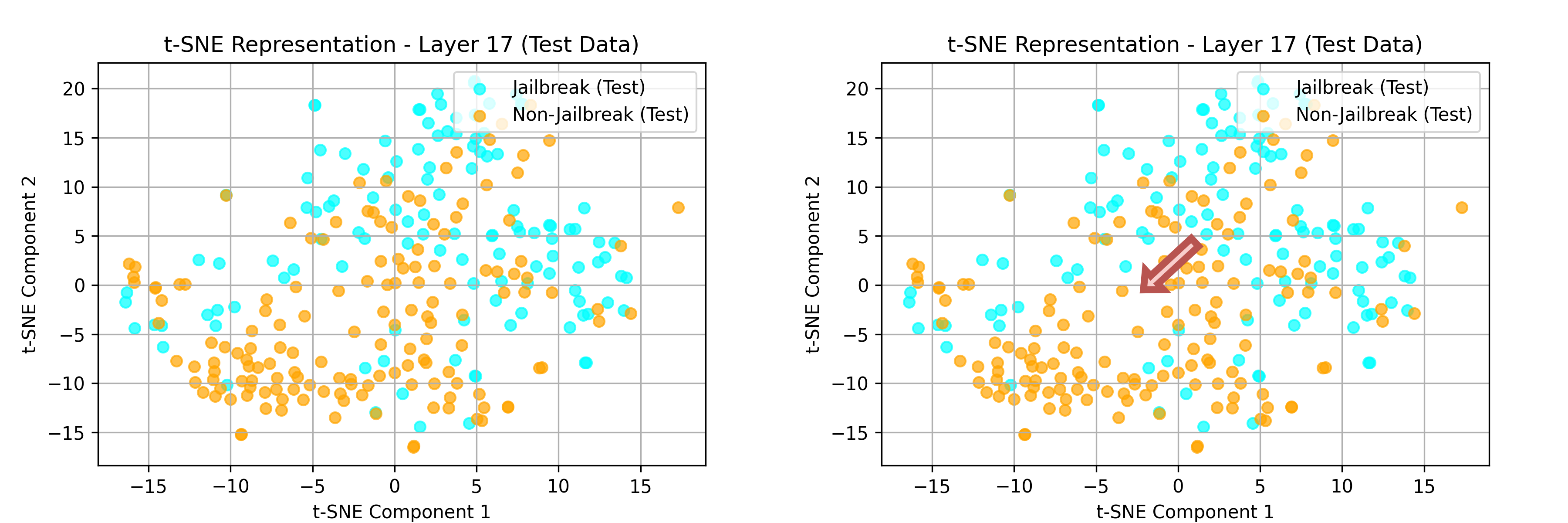
This difference can become clearer by using and training t-SNE. Therefore, there may actually be a consistent difference that we can add or subtract to control the direction of the activations.
Ultimately, our goal is to push the "Jailbreak" activations into the "Non-Jailbreak" area.
In summary:
No meaningful differences were found between activations in layers 1 and 3.
Early layers do not show clear separation between jailbreak and non-jailbreak responses.
As the prompt propagates deeper into the model, slight separation begins to appear.
Let’s intervene!
Since we collected activations for both jailbreak and non-jailbreak prompts, I computed their averages and extracted the difference to determine a "direction."
Layer 17 showed clear divergence between jailbroken and non-jailbroken responses, making it the primary focus.
prompts_jailbreaking = np.load("prompts_jailbreaking.npy", allow_pickle=True)
no_prompts_jailbreaking = np.load("no_prompts_jailbreaking.npy", allow_pickle=True)
prompts_jailbreaking = np.array(prompts_jailbreaking).reshape(len(prompts_jailbreaking), 28, 3072)
no_prompts_jailbreaking = np.array(no_prompts_jailbreaking).reshape(len(no_prompts_jailbreaking), 28, 3072)
layer_idx = 17
layer_data_jailbreak = prompts_jailbreaking[:, layer_idx, :]
layer_data_non_jailbreak = no_prompts_jailbreaking[:, layer_idx, :] # (samples, features)
# Compute the mean activation across samples for both conditions
mean_activation_jailbreak = np.mean(layer_data_jailbreak, axis=0)
mean_activation_non_jailbreak = np.mean(layer_data_non_jailbreak, axis=0)
activation_difference = mean_activation_jailbreak mean_activation_non_jailbreakThis returns a “direction,” and depending on whether it is negative or positive, we can modify the activations accordingly.
The following function is triggered whenever text is generated. As observed, steering_vec is responsible for adding or subtracting the direction
def act_add(steering_vec, k):
def hook(output):
steering_vec_array = np.array(steering_vec.cpu())
top_k_indices = np.argsort(np.abs(steering_vec_array))[-k:]
mask = np.zeros_like(steering_vec_array)
mask[top_k_indices] = 1
steering_vec_masked = steering_vec_array * mask
steering_vec_masked = torch.tensor(steering_vec_masked).to('cuda')
return (output[0] + steering_vec_masked,) + output[1:]
return hook
Results:
Adding the direction to Layer 17 led to 85% of the same prompts triggering an illegal response.
Subtracting the direction led to 75% of the same prompts rejecting the illegal response, becoming more resilient.
This demonstrates the hypothesis and highlights activation-level interventions as a viable approach. What is more, looking again at the PCA we can observe they are different, with less noticeable patterns.
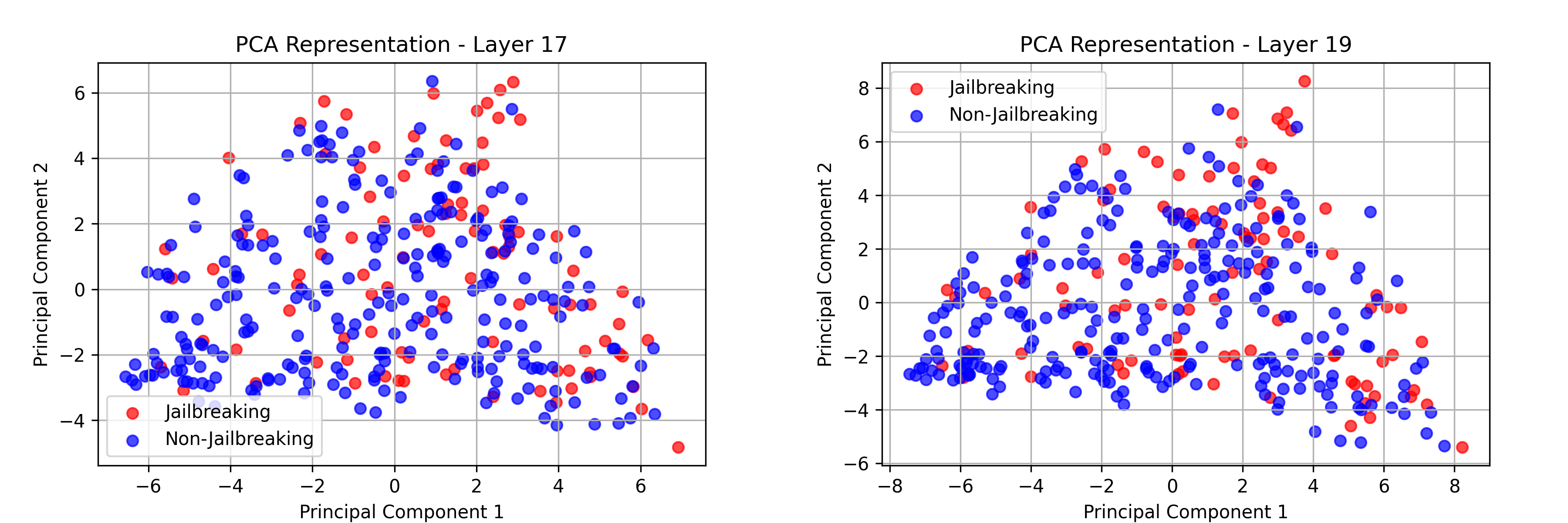
Further steps
While I have utilized a diverse array of jailbreak prompts and instructions, my analysis was limited to a single model due to time constraints. Expanding this research to include multiple models could reveal universal activation patterns associated with jailbreak behaviors. Recent studies suggest that certain features and activation patterns are conserved across different language models. For instance, research has demonstrated a local mapping between activation spaces of two language models that preserves language modeling loss, indicating the presence of universal representations.
Additionally, investigations into feature universality have found that different models similarly represent concepts in their intermediate layers, suggesting the existence of shared activation patterns.
By analyzing multiple models, we may identify common "directions" in activation space that could be leveraged to develop more robust intervention strategies against jailbreak prompts.
Summary
This project investigates the detection and mitigation of jailbroken modes in large language models (LLMs). By analyzing activation patterns, I aim to identify specific differences between jailbreak and non-jailbreak responses. Through experimentation with TrustAIRLab datasets and the Llama-3.2-3B-Instruct model, I examined activation variations across layers and discovered a notable divergence at Layer 17. Using this insight, I developed an intervention strategy that modifies model activations to reduce the likelihood of generating illicit responses. The results show that adding or subtracting this learned activation direction significantly impacts the model’s behavior, supporting the hypothesis that jailbreak detection and intervention can be achieved at an activation level.
Final Thoughts & Thank You
This project has been a fascinating exploration into mechanistic interpretability and AI safety. The insights gained reinforce the importance of studying LLM activations to develop better security mechanisms against adversarial prompting.
I want to extend my deepest gratitude to the BlueDot Institute for their invaluable support and to Cara for her mentorship throughout this journey. A special thank you to my peers in this course—your enthusiasm and collaboration have been truly inspiring.
I look forward to continuing this research and contributing further to AI alignment efforts. If you have any thoughts, questions, or feedback, feel free to reach out!
The code is public in here → https://github.com/Luisibear98/intervention-jailbreak
However I did not have too much time to clean and prepare it, I Will eventually improve it :)
References
[1] Anthropic. (2025). Recommended Directions for AI Alignment Research. Retrieved from https://alignment.anthropic.com/2025/recommended-directions.
[2] Anthropic. (2023). Alignment Faking in Language Models. Retrieved from https://www.anthropic.com/research/alignment-faking.
[3] Ma, X., et al. (2024). Faithful Chain-of-Thought Reasoning. arXiv:2402.14897.
[4] Abdelnabi, S., Fay, A., Cherubin, G., Salem, A., Fritz, M., & Paverd, A. (2024). Are you still on track!? Catching LLM Task Drift with Activations. arXiv:2406.00799.