



Decodificación especulativa: menor latencia, sin sacrificar calidad
Embarquémonos en un viaje con múltiples desvíos, en los que profundizaremos en el mecanismo de funcionamiento de los transformers

Los modelos de lenguaje de gran tamaño (large language models, o LLM) han revolucionado el campo del procesamiento de lenguaje natural.
Hasta el momento, muchas de las mejoras en las capacidades de estos modelos han venido de la mano de incrementos en su número de parámetros; estos incrementos, a su vez, han supuesto un aumento sustancial de los costes computacionales de su puesta en producción.
Por otro lado, estas mejoras han abierto paso al despliegue masivo de estos modelos para múltiples casos de uso, y las expectativas de calidad, robustez y velocidad también han aumentado.
En este artículo exploraremos la técnica de decodificación especulativa, la cual busca una reducción en la latencia de las predicciones realizadas con LLM.
Además, profundizaremos sobre el mecanismo de funcionamiento de los transformers, mostrando en detalle el proceso de generación de texto.
Inferencia en modelos autorregresivos
Para comprender cómo acelerar la inferencia de nuestros modelos, primero necesitamos identificar cuáles son los cuellos de botella; para ello, haremos un repaso sobre el mecanismo de generación de los LLM.
Una característica común entre los LLM enfocados en tareas de generación es que son autorregresivos: realizan predicciones de secuencias elemento a elemento (token a token), utilizando aquellos generados en pasos previos como entradas para la generación del siguiente.

Esto significa que, para la generación de una secuencia de n elementos, el modelo debe realizar un total de n predicciones.
El problema es que cada una de estas predicciones depende a su vez de los resultados de las predicciones de los elementos que la preceden en la secuencia, por lo que el proceso de generación no es paralelizable. Esto implica una latencia proporcional a la longitud de la secuencia generada.

¿Por qué esto supone un problema? A medida que aumentamos la complejidad (i.e., tamaño) de nuestros modelos, cada propagación hacia adelante supone un coste computacional (y, por ende, temporal) considerable.
Las GPUs (o TPUs) están diseñadas con arquitecturas optimizadas para la paralelización masiva de operaciones. Para aprovechar al máximo su rendimiento, es necesario aumentar el número de consultas o predicciones procesadas simultáneamente en cada propagación hacia adelante.
Pese a que el mecanismo de atención utilizado en los transformers sí se procesa en paralelo, debido a las codependencias entre las predicciones de los elementos de la secuencia, no podemos generar múltiples tókenes en paralelo.
Pero, entonces, si no hay manera de evitar la generación secuencial de los elementos, ¿cómo podemos reducir la latencia de las predicciones?
Existen opciones como la cuantización (que explicaremos en otro post), la cual disminuye la latencia de las predicciones al reducir la precisión de los pesos del modelo, pero esta conlleva una degradación o pérdida de calidad en los resultados obtenidos.
La decodificación especulativa nos ofrece un método alternativo que no requiere modificaciones sobre el modelo original, garantizando un resultado idéntico al obtenido utilizando el modelo de manera secuencial.
La idea
La decodificación especulativa propone utilizar un modelo más sencillo (i.e., con un menor número de parámetros) como aproximación de las predicciones de un modelo más complejo, buscando minimizar el número de predicciones secuenciales realizadas por este último.
¿Por qué es especulativa? Porque las predicciones del modelo más sencillo (referido como modelo especulativo de ahora en adelante) deben ser verificadas para confirmar que coinciden con aquellas generadas por el modelo más complejo.
La decodificación especulativa funciona bajo la premisa de que el problema del modelado de lenguaje está a su vez compuesto por sub-problemas de menor complejidad, los cuales pueden ser resueltos por modelos más sencillos.
En detalle
Lo primero que tenemos que tener claro es que el objetivo de la decodificación especulativa no es la de reducir los costes computacionales asociados a las predicciones, si no la de reducir la latencia de las mismas, a costa de un mayor coste espacial (dado que requerimos cargar dos modelos en memoria, en lugar de un único modelo).
Ya hemos mencionado que la predicción en cualquier modelo autoregresivo es secuencial, independientemente de la complejidad (tamaño) del mismo. Pese a que el modelo más sencillo también realizará sus predicciones token a token, dado su menor tamaño, será capaz de realizar un mayor número de predicciones por unidad de cómputo.
No obstante, si como ya hemos mencionado, las predicciones del modelo más sencillo deben ser verificadas, y siguen siendo generadas de manera secuencial, ¿cuál es el factor que reduce la latencia de la generación?
La clave está en que la verificación de los tokens especulativos requiere una única propagación hacia adelante por parte del modelo complejo.
Esto nos permite aprovechar las capacidades más avanzadas del modelo más complejo reduciendo drásticamente el número de propagaciones hacia adelante realizadas por el mismo.
Generación de tókenes especulativos
El proceso de generación de tókenes especulativos se realiza en grupos de γ (gamma) tókenes.
Generar los tókenes especulativos en grupos permite amortizar el coste asociado a cada propagación hacia adelante del modelo más complejo, distribuyéndolo entre la mayor cantidad posible de tókenes verificados.
Es importante recordar que la verificación de los tókenes especulativos se lleva a cabo en paralelo, mediante una única propagación hacia adelante del modelo más complejo.
No obstante, es fundamental encontrar un equilibrio óptimo en el número de tókenes secuenciales generados (y verificados) en cada pasada.
A medida que aumenta el número de tókenes especulativos generados, también crece la probabilidad de que estos tókenes generados sean inválidos, lo que incrementa el riesgo de computaciones que deberán ser descartadas.
Cabe remarcar que, pese a que aquellos tókenes especulativos rechazados suponen una cierta cantidad de unidades de cómputo desechadas, el coste computacional de estas es menor, dado el menor tamaño del modelo (en comparación con el modelo más complejo).
Verificación de tókenes especulativos
De manera más abstracta, la verificación consiste en la comparación de las distribuciones de salida de ambos modelos para cada token especulativo generado.
La idea general es que si ambas distribuciones son lo suficientemente similares, aceptaremos como válidas las predicciones realizadas por el modelo especulativo.
En el caso de que las distribuciones de salida diverjan, rechazaremos esa predicción y las subsecuentes, reemplazándola por un nuevo token obtenido a partir de la distribución generada por el modelo complejo.

Pero, ¿por qué hablamos de comparar distribuciones de salida en lugar de tokens generados?
Hablamos de distribuciones en lugar de tókenes porque este método es generalizable para cualquier estrategia de muestreo aplicada sobre las distribuciones de salida del modelo.
Recordemos que la salida de los LLM autorregresivos no son tókenes como tal, sino distribuciones de probabilidad sobre el vocabulario utilizado en el proceso de tokenización.
De manera más concreta, el proceso de verificación compara la densidad de probabilidad asociada al token generado en cada posición por el modelo más complejo, y el modelo especulativo.
En el caso de que la densidad de probabilidad asociada al token especulativo sea menor o igual que la asociada por el modelo más complejo, el token será aceptado.
En el caso contrario, se rechazarán ese token, y todos aquellos posteriores (dado que la validez de estos depende de la validez de sus predecesores), reemplazándolo por un nuevo token muestreado a partir de la distribución de salida del modelo complejo.
Esto significa que, incluso en el peor de los casos, la propagación hacia adelante realizada con el modelo complejo nunca es en vano, ya que o bien aprovecharemos para reemplazar un token rechazado por otro, o bien agregaremos un token adicional a la secuencia.
Pero, ¿por qué rechazamos aquellos tókenes cuya densidad de probabilidad asociada es mayor en el modelo especulativo que en el modelo más grande?
Esto se debe a que lo que buscamos con este método es aproximar las distribuciones de salida generadas por el modelo complejo; por lo tanto, entendemos aquellos casos en los que, para un mismo token, el modelo especulativo haya asignado una mayor probabilidad que el modelo más grande, como sobreestimaciones, y, por lo tanto, serán rechazadas.
Recordemos que el modelo más grande es, por definición, más preciso; por ello, no contradeciremos las predicciones realizadas por el modelo más grande por aquellas realizadas por el modelo especulativo.
Transformers, paso a paso
Vamos a repasar paso a paso el mecanismo de funcionamiento de los transformers para comprender el porqué detrás de la decodificación especulativa.
Enfoquémonos primero en la entrada del transformer. El bloque recibe un tensor (matriz) resultante de la cadena de transformación ilustrada a continuación.

Tokenización: el texto original es dividido en tókenes a partir de un diccionario predefinido.
Embedding: obtenemos una representación densa a partir de los tókenes obtenidos. Estos vectores codifican información semántica sobre los tókenes.
Encoding posicional: agregamos información a los embeddings obtenidos sobre la posición que ocupa el token en la secuencia original. Esto es necesario debido a que los transformers son invariantes a la permutación: sin el encoding posicional, los transformers no diferenciarían entre las secuencias “España descubrió América” y “América descubrió España”.
A partir de este momento, el transformer procesará las representaciones obtenidas para cada token de la secuencia en paralelo, generando una nueva representación contextualizada para cada token de entrada.
Este es el punto crucial sobre el que se basa el método de la decodificación especulativa: estas representaciones se generan para todos los tokens de la secuencia, y además se realizan en paralelo, requiriendo una única propagación hacia adelante.
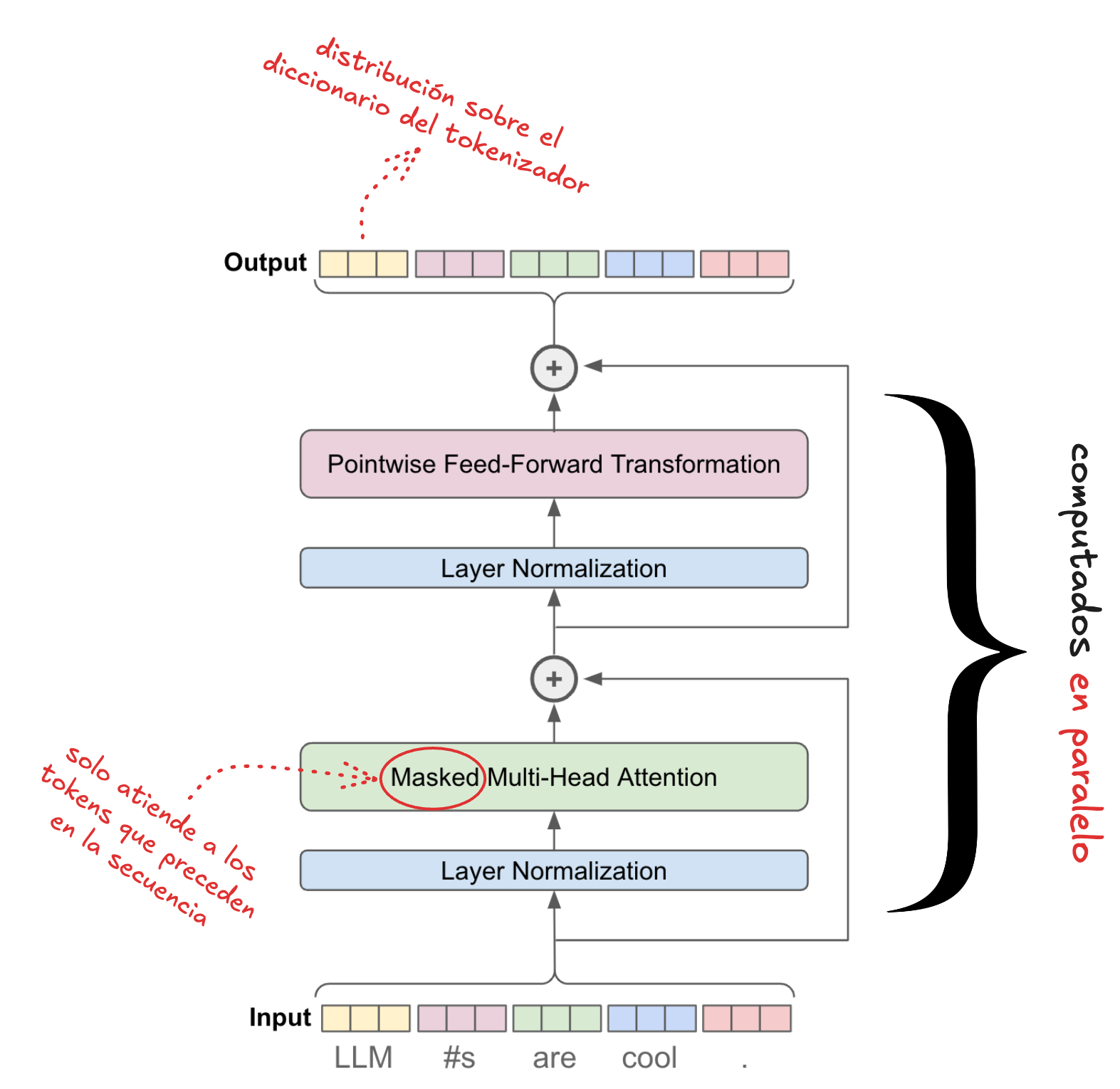
Es importante destacar que la representación contextualizada obtenida estará alineada con la tarea específica para la cual estamos entrenando el modelo.
En modelos autorregresivos la representación contextualizada generada por el transformer está enfocada en la predicción del próximo token. Es decir, la distribución de salida generada para cada token en una posición corresponde a la probabilidad del próximo token en esa posición. De esta manera, cada token “predice” el siguiente en la secuencia, permitiendo la generación autorregresiva, elemento a elemento.
Para lograr esto, el mecanismo de atención en los modelos autorregresivos introduce una modificación respecto al mecanismo original. En el mecanismo de atención estándar, se permite la atención bidireccional, es decir, la representación obtenida para un elemento de la secuencia puede basarse tanto en los elementos que lo preceden como en los que lo suceden. En los modelos autorregresivos, sin embargo, el mecanismo de atención se restringe únicamente a los elementos que preceden al token actual en la secuencia, enmascarando u ocultando los que le siguen.

Con este enfoque, se evita que el modelo “haga trampa”: si no se ocultaran los tókenes futuros, el modelo no sería capaz de aprender a predecir el próximo token de manera efectiva, ni sería capaz de generalizar correctamente.
Una vez procesados por el mecanismo de atención, obtenemos lo que se denominan como embeddings contextualizados. Estos embeddings contextualizados incorporan información semántica sobre la secuencia; esto implica que la representación obtenida para un mismo token presente en dos secuencias distintas será diferente.

Estas representaciones son proyectadas hacia el espacio vectorial del diccionario utilizado por el tokenizador (i.e., el vocabulario utilizado).
Finalmente, el resultado de la proyección sufre una última transformación, aplicando la función exponencial normalizada (SoftMax), la cual comprime los valores del vector proyectado en el rango [0,1]. Esto produce una distribución de probabilidad sobre el diccionario.
El paso final en el proceso de generación es muestrear la distribución de salida obtenida para así materializar la predicción.
En el caso de la decodificación especulativa, el método de muestreo que escojamos en este paso debe ser el idéntico para ambos modelos.
Existen múltiples métodos de muestreo sobre la distribución de salida. La idea general es la de manipular el vector de salida del transformer proyectado sobre el diccionario, para así guiar el resultado del muestreo.

En el más simple de los casos, la estrategia de greedy decoding se basa en seleccionar aquel token del diccionario con mayor probabilidad asociada en la distribución obtenida.
A diferencia de los casos generativos, en los que buscamos generar un nuevo token por cada propagación hacia adelante, muestreando únicamente la última posición, en el caso de la decodificación especulativa, muestrearemos todas las posiciones para las cuales debamos verificar tokens especulativos.
Más allá

Una implementación alternativa para realizar decodificación especulativa a la que hemos cubierto en este artículo es Medusa.
Medusa parte de las mismas premisas, pero no requiere de un modelo especulativo para la generación de tókenes especulativos (i.e., candidatos).
En su lugar, propone agregar múltiples decoding heads sobre la salida del bloque transformer del modelo, previa proyección en la referida como LM (language modeling) head.
En esencia, estas decoding heads nos permiten, en una única propagación hacia adelante sobre el modelo original, predecir múltiples tókenes de manera simultánea.
Cada una de las medusa heads predice tokénes en posiciones futuras (i.e., cabeza n predice token (t + (n + 1)), en paralelo.
Tenéis más información disponible sobre Medusa, ejemplos de modelos ya fine-tuned para probar en inferencia, así como un notebook guía para agregar las cabezas medusa en el siguiente link.
Si has encontrado este artículo útil, te animo a suscribirte a la publicación (completamente gratuito) para recibir próximas entregas directamente en tu Email 😊
Y si crees que puede interesarle a alguien, te agradeceríamos enormemente que lo compartieses 🔗